Stereo disparity edge maps
[Audio Version]
I've been experimenting further with stereo vision. Recently, I made a small breakthrough that I thought worth describing for the benefit of other researchers working toward the same end.
One key goal of mine with respect to stereo vision has been the same as for most involved in the subject: being able to tell how far away things in a scene are from the camera or, at least, relative to one another. If you wear glasses or contact lenses, you've probably seen that test of your depth perception in which you look through polarizing glasses at a sheet of black rings and attempt to tell which one looks like it is "floating" above the others. It's astonishing to me just how little disparity there has to be between images in one's left and right eyes in order for one to tell which ring is different from the others.
Other researchers have used a variety of techniques for getting a machine to have this sort of perception. I am currently using a combination of techniques. Let me describe them briefly.
 First, when the program starts up, the eyes have to get focused on the same thing. Both eyes start out with a focus box -- a rectangular region smaller than the image each eye sees and analogous to the human fovea -- that is centered on the image. The first thing that happens once the eyes see the world is that the focus boxes are matched up using a basic patch equivalence technique. In this case, a "full alignment" involves moving the right eye's focus patch in a grid pattern over the whole field of view of the right eye in large increments (e.g., 10 pixels horizontally and vertically). The best-matching place then becomes the center of a second scan in single pixel increments in a tighter region to find precisely the best matching placement for the right field of view.
First, when the program starts up, the eyes have to get focused on the same thing. Both eyes start out with a focus box -- a rectangular region smaller than the image each eye sees and analogous to the human fovea -- that is centered on the image. The first thing that happens once the eyes see the world is that the focus boxes are matched up using a basic patch equivalence technique. In this case, a "full alignment" involves moving the right eye's focus patch in a grid pattern over the whole field of view of the right eye in large increments (e.g., 10 pixels horizontally and vertically). The best-matching place then becomes the center of a second scan in single pixel increments in a tighter region to find precisely the best matching placement for the right field of view.
The full alignment operation is expensive in terms of time: about three seconds on my laptop. With every tenth snapshot taken by the eyes, I perform a "horizontal alignment", a trimmed-down version of the full alignment. This time, however, the test does not involve moving the right focus box up or down relative to its current position; only left and right. This, too, can be expensive: about 1 second for me. So finally, with each snapshot taken, I perform a "lite" horizontal alignment, which involves looking a little to the left and to the right of the current position of the focus box. This takes less than a second on my laptop, which is definitely worth making it standard with each snapshot. The result is that the eyes generally line their focus boxes up quickly on the objects in the scene as they are pointed at different viewpoints. If the jump is too dramatic for the lite horizontal alignment process, eventually the full horizontal alignment process corrects for that.
Once the focus boxes are lined up, the next step is clear. For each part of the scene that is in the left focus box, look for its mate in the right focus box. Then calculate how many pixels offset the left and right versions are from each other. Those with zero offsets are at a "neutral" distance, relative to the focus boxes. Those with the right versions' offsets being positive (a little to the right) are probably farther away. And those with the right hand features having negative offsets (a little to the left) are probably closer. This much is conventional wisdom. And the math is actually simple enough that one can even estimate absolute distances from the camera, given that some numeric factors about the cameras are known in advance.
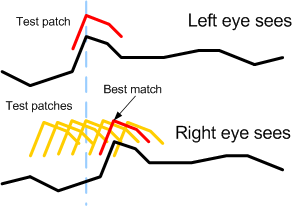 The important question, then, is how to match features in the left focus box with the same features in the right. I chose to use a variant of the same patch equivalence technique I use for lining up the focus boxes. In this case, I break down the left focus box into a lot of little patches -- one for each pixel in the box. Each patch is about 9 pixels wide. What's interesting, though, is that I'm using 1-dimensional patches, which means each patch is only one pixel high. For each patch in this tight grid of (overlapping) patches in the left focus box, there is a matching patch in the right focus box, too. Initially, its center is exactly the same as for the left one, relative to the focus box. For each patch in the left side, then, we move its right-hand mate from left to right from about -4 to +4 pixels. Whichever place yields the lowest difference is considered the best match. That place, then, is considered to be where the right-hand pixel is for the one we're considering on the left, and hence we have our horizontal offset.
The important question, then, is how to match features in the left focus box with the same features in the right. I chose to use a variant of the same patch equivalence technique I use for lining up the focus boxes. In this case, I break down the left focus box into a lot of little patches -- one for each pixel in the box. Each patch is about 9 pixels wide. What's interesting, though, is that I'm using 1-dimensional patches, which means each patch is only one pixel high. For each patch in this tight grid of (overlapping) patches in the left focus box, there is a matching patch in the right focus box, too. Initially, its center is exactly the same as for the left one, relative to the focus box. For each patch in the left side, then, we move its right-hand mate from left to right from about -4 to +4 pixels. Whichever place yields the lowest difference is considered the best match. That place, then, is considered to be where the right-hand pixel is for the one we're considering on the left, and hence we have our horizontal offset.
For the large fields of homogenous color in a typical image, it doesn't make sense to use patch equivalence testing. It makes more sense to focus instead on the strong features in the image. So to the above, I added a traditional Sobel edge detection algorithm. I use it to scan the right focus box, but I only use the vertical test. That means I find strong, vertical edges and largely ignore strong horizontal edges. Why do this? Stereo disparity tests with two eyes side by side only work well with strong vertical features. So only pixels in the image that get high values from the Sobel test are considered using the above technique.
This whole operation takes a little under a second on my laptop -- not bad.
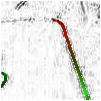
Following are some preliminary image sets that show test results. Here's how to interpret them. The first two images in each set are the left and right fields of view, respectively. The third image is a "result" image. That is, it shows features within the focus box and indicates their relative distance to the camera. Strongly green features are closer to, strongly red features are farther away, and black features are at relatively neutral distances, with respect to the focus box pair. The largely white areas represent areas with few strong vertical features and are hence ignored in the tests.
In all, I'm impressed with the results. One can't say that the output images are unambiguous in what they say about perceived relative distance. Some far-away objects show tinges of green and some nearby objects show have tinges of red, which of course doesn't make sense. Yet overall, there are strong trends that suggest this technique is actually working. With some good engineering, the quality of results can be improved. Better cameras wouldn't hurt, either.
One thing I haven't addressed yet is the "white" areas. A system based on this might see the world as though it were made up of "wire frame" objects. If I want to have a vision system that's aware of things as being solid and having substance, it'll be necessary to determine how far away the areas among the sharp vertical edges are, too. I'm certain that a lot of that has to do with inferences our visual systems make based on the known edges and knowledge of how matter works. Obviously, I have a long way to go to achieve that.
I've been experimenting further with stereo vision. Recently, I made a small breakthrough that I thought worth describing for the benefit of other researchers working toward the same end.
One key goal of mine with respect to stereo vision has been the same as for most involved in the subject: being able to tell how far away things in a scene are from the camera or, at least, relative to one another. If you wear glasses or contact lenses, you've probably seen that test of your depth perception in which you look through polarizing glasses at a sheet of black rings and attempt to tell which one looks like it is "floating" above the others. It's astonishing to me just how little disparity there has to be between images in one's left and right eyes in order for one to tell which ring is different from the others.
Other researchers have used a variety of techniques for getting a machine to have this sort of perception. I am currently using a combination of techniques. Let me describe them briefly.
First, when the program starts up, the eyes have to get focused on the same thing. Both eyes start out with a focus box -- a rectangular region smaller than the image each eye sees and analogous to the human fovea -- that is centered on the image. The first thing that happens once the eyes see the world is that the focus boxes are matched up using a basic patch equivalence technique. In this case, a "full alignment" involves moving the right eye's focus patch in a grid pattern over the whole field of view of the right eye in large increments (e.g., 10 pixels horizontally and vertically). The best-matching place then becomes the center of a second scan in single pixel increments in a tighter region to find precisely the best matching placement for the right field of view. The full alignment operation is expensive in terms of time: about three seconds on my laptop. With every tenth snapshot taken by the eyes, I perform a "horizontal alignment", a trimmed-down version of the full alignment. This time, however, the test does not involve moving the right focus box up or down relative to its current position; only left and right. This, too, can be expensive: about 1 second for me. So finally, with each snapshot taken, I perform a "lite" horizontal alignment, which involves looking a little to the left and to the right of the current position of the focus box. This takes less than a second on my laptop, which is definitely worth making it standard with each snapshot. The result is that the eyes generally line their focus boxes up quickly on the objects in the scene as they are pointed at different viewpoints. If the jump is too dramatic for the lite horizontal alignment process, eventually the full horizontal alignment process corrects for that.
Once the focus boxes are lined up, the next step is clear. For each part of the scene that is in the left focus box, look for its mate in the right focus box. Then calculate how many pixels offset the left and right versions are from each other. Those with zero offsets are at a "neutral" distance, relative to the focus boxes. Those with the right versions' offsets being positive (a little to the right) are probably farther away. And those with the right hand features having negative offsets (a little to the left) are probably closer. This much is conventional wisdom. And the math is actually simple enough that one can even estimate absolute distances from the camera, given that some numeric factors about the cameras are known in advance.
The important question, then, is how to match features in the left focus box with the same features in the right. I chose to use a variant of the same patch equivalence technique I use for lining up the focus boxes. In this case, I break down the left focus box into a lot of little patches -- one for each pixel in the box. Each patch is about 9 pixels wide. What's interesting, though, is that I'm using 1-dimensional patches, which means each patch is only one pixel high. For each patch in this tight grid of (overlapping) patches in the left focus box, there is a matching patch in the right focus box, too. Initially, its center is exactly the same as for the left one, relative to the focus box. For each patch in the left side, then, we move its right-hand mate from left to right from about -4 to +4 pixels. Whichever place yields the lowest difference is considered the best match. That place, then, is considered to be where the right-hand pixel is for the one we're considering on the left, and hence we have our horizontal offset. For the large fields of homogenous color in a typical image, it doesn't make sense to use patch equivalence testing. It makes more sense to focus instead on the strong features in the image. So to the above, I added a traditional Sobel edge detection algorithm. I use it to scan the right focus box, but I only use the vertical test. That means I find strong, vertical edges and largely ignore strong horizontal edges. Why do this? Stereo disparity tests with two eyes side by side only work well with strong vertical features. So only pixels in the image that get high values from the Sobel test are considered using the above technique.
This whole operation takes a little under a second on my laptop -- not bad.
Following are some preliminary image sets that show test results. Here's how to interpret them. The first two images in each set are the left and right fields of view, respectively. The third image is a "result" image. That is, it shows features within the focus box and indicates their relative distance to the camera. Strongly green features are closer to, strongly red features are farther away, and black features are at relatively neutral distances, with respect to the focus box pair. The largely white areas represent areas with few strong vertical features and are hence ignored in the tests.
 |  |  |
 |  |  |
 |  |  |
 |  |  |
 |  |  |
 |  |  |
In all, I'm impressed with the results. One can't say that the output images are unambiguous in what they say about perceived relative distance. Some far-away objects show tinges of green and some nearby objects show have tinges of red, which of course doesn't make sense. Yet overall, there are strong trends that suggest this technique is actually working. With some good engineering, the quality of results can be improved. Better cameras wouldn't hurt, either.
One thing I haven't addressed yet is the "white" areas. A system based on this might see the world as though it were made up of "wire frame" objects. If I want to have a vision system that's aware of things as being solid and having substance, it'll be necessary to determine how far away the areas among the sharp vertical edges are, too. I'm certain that a lot of that has to do with inferences our visual systems make based on the known edges and knowledge of how matter works. Obviously, I have a long way to go to achieve that.

Comments
Post a Comment