Stereo vision: measuring object distance using pixel offset
[Audio Version]
I've had some scraps of time here and there to put toward progress on my stereo vision experiments. My previous blog entry described how to calibrate a stereo camera pair to find X and Y offsets that correspond in the right camera with the same position in the left camera when they are both looking at a far off "infinity point". Once I had that, I knew it was only a small step to use the same basic algorithm for dynamically getting the two cameras "looking" at the same thing even when the subject matter is close enough for the two cameras to actually register a difference. And since I have the vertical offset already calculated, I was happy to see the algorithm running along this single horizontal "rail" runs faster.
The next logical step, then, was to see if I could figure out the formula for telling how far away what the cameras are looking at is from the cameras. This is one of the core reasons for using a pair of cameras instead of one. I looked around the web for some useful explanation or diagrams. I found lots of inadequate diagrams that show the blatantly obvious, but nothing that was complete enough to develop a solution from.
So I decided to develop my own solution using some basic trigonometry. It took a while and a few headaches, but I finally got it down. I was actually surprised at how well it worked. I thought I should publish the method I used in detail so other developers can get past this more quickly. The following diagram graphically illustrates the concept and the math, which I explain further below.
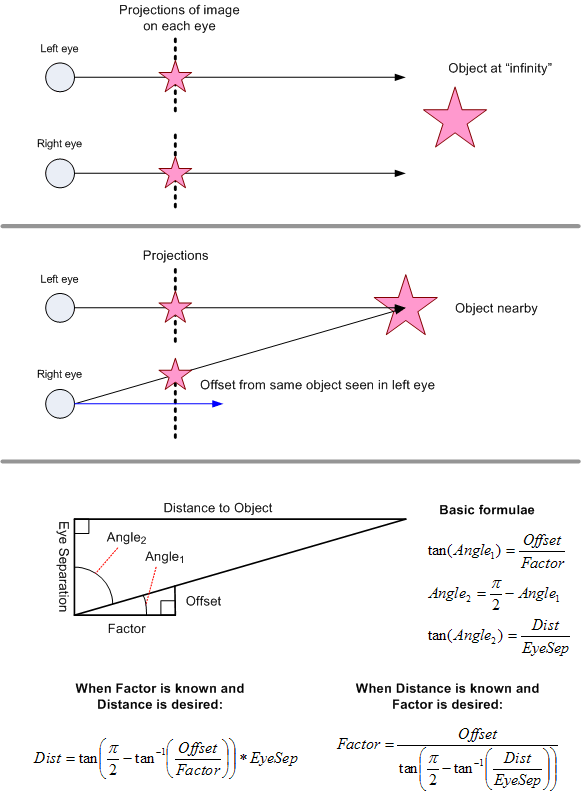
I suppose I'm counting on you knowing what the inputs are. If you do, skip the next paragraph. Otherwise, this may help.
 The pink star represents some object that the two cameras are looking at. Let's assume the cameras are perfectly aligned with each other. That is, when the object is sufficiently far away -- say, 30 feet or more for cameras that are 2.5 inches apart -- and you blend the images from both cameras, the result looks the same as if you just looked at the left or right camera image. But if you stick your hand in front of the camera pair at, say, 5 feet away and look at the combined image, you see two "hands" partly overlapping. Let's say you measured the X (horizontal) offset of one version of the hand from the other as being about 20 pixels. Now, you change the code to overlap the pictures so that the right-hand one is offset by 20 pixels. Now the two hands perfectly overlap and it's the background scene that's doubled-up. The diagram above is suggestive of this in the middle section, where the pink star is in different places in the left and right camera "projections". These projections are really just the images that are output. Now that you grasp the idea that the object seen by the two cameras is the same, but simply offset to different positions in each image, we can move on. Assume for now that we already have code that can measure the offset in pixels I describe above.
The pink star represents some object that the two cameras are looking at. Let's assume the cameras are perfectly aligned with each other. That is, when the object is sufficiently far away -- say, 30 feet or more for cameras that are 2.5 inches apart -- and you blend the images from both cameras, the result looks the same as if you just looked at the left or right camera image. But if you stick your hand in front of the camera pair at, say, 5 feet away and look at the combined image, you see two "hands" partly overlapping. Let's say you measured the X (horizontal) offset of one version of the hand from the other as being about 20 pixels. Now, you change the code to overlap the pictures so that the right-hand one is offset by 20 pixels. Now the two hands perfectly overlap and it's the background scene that's doubled-up. The diagram above is suggestive of this in the middle section, where the pink star is in different places in the left and right camera "projections". These projections are really just the images that are output. Now that you grasp the idea that the object seen by the two cameras is the same, but simply offset to different positions in each image, we can move on. Assume for now that we already have code that can measure the offset in pixels I describe above.
Once I got through the math, I made a proof of concept rig to calculate distance. I simply tweaked the "factor" constant by hand until I started getting distances to things in the room that jibed with what my tape measure said. Then I went on to work the math backward so that I could enter a measured distance and have it calculate the factor, instead. I packaged that up into a calibration tool.
I expected it would work fairly well, but I was truly surprised at how accurate it is, given the cheap cameras I have and the low resolution of the images they output. I found with objects I tested from two to ten feet away, the estimated distance was within two inches of what I measured using a tape measure. That's accurate enough, in my opinion, to build a crude model of a room for purposes of navigating through it, a common task in AI for stereo vision systems.
I haven't yet seen how good it is at distinguishing distance in objects that are very close to one another using this mechanism. We can easily discriminate depth offsets of a millimeter on objects within two feet. These cameras are not that good, so I doubt they'll be as competent.
So now I have a mechanism that does pretty well at taking a rectangular portion of a scene and finding the best match it can for that portion in the other eye and using it to calculate the distance based on the estimated offset. The next step, then, is to repeat this over the entire image and with ever smaller rectangular regions. I can already see some important challeges, like what to do when the rectangle just contains a solid color or a repeating pattern, but these seem modest complications to an otherwise fairly simple technique. Cool.
[See also Automatic Alignment of Stereo Sameras.]
I've had some scraps of time here and there to put toward progress on my stereo vision experiments. My previous blog entry described how to calibrate a stereo camera pair to find X and Y offsets that correspond in the right camera with the same position in the left camera when they are both looking at a far off "infinity point". Once I had that, I knew it was only a small step to use the same basic algorithm for dynamically getting the two cameras "looking" at the same thing even when the subject matter is close enough for the two cameras to actually register a difference. And since I have the vertical offset already calculated, I was happy to see the algorithm running along this single horizontal "rail" runs faster.
The next logical step, then, was to see if I could figure out the formula for telling how far away what the cameras are looking at is from the cameras. This is one of the core reasons for using a pair of cameras instead of one. I looked around the web for some useful explanation or diagrams. I found lots of inadequate diagrams that show the blatantly obvious, but nothing that was complete enough to develop a solution from.
So I decided to develop my own solution using some basic trigonometry. It took a while and a few headaches, but I finally got it down. I was actually surprised at how well it worked. I thought I should publish the method I used in detail so other developers can get past this more quickly. The following diagram graphically illustrates the concept and the math, which I explain further below.
I suppose I'm counting on you knowing what the inputs are. If you do, skip the next paragraph. Otherwise, this may help.
The pink star represents some object that the two cameras are looking at. Let's assume the cameras are perfectly aligned with each other. That is, when the object is sufficiently far away -- say, 30 feet or more for cameras that are 2.5 inches apart -- and you blend the images from both cameras, the result looks the same as if you just looked at the left or right camera image. But if you stick your hand in front of the camera pair at, say, 5 feet away and look at the combined image, you see two "hands" partly overlapping. Let's say you measured the X (horizontal) offset of one version of the hand from the other as being about 20 pixels. Now, you change the code to overlap the pictures so that the right-hand one is offset by 20 pixels. Now the two hands perfectly overlap and it's the background scene that's doubled-up. The diagram above is suggestive of this in the middle section, where the pink star is in different places in the left and right camera "projections". These projections are really just the images that are output. Now that you grasp the idea that the object seen by the two cameras is the same, but simply offset to different positions in each image, we can move on. Assume for now that we already have code that can measure the offset in pixels I describe above. Once I got through the math, I made a proof of concept rig to calculate distance. I simply tweaked the "factor" constant by hand until I started getting distances to things in the room that jibed with what my tape measure said. Then I went on to work the math backward so that I could enter a measured distance and have it calculate the factor, instead. I packaged that up into a calibration tool.
I expected it would work fairly well, but I was truly surprised at how accurate it is, given the cheap cameras I have and the low resolution of the images they output. I found with objects I tested from two to ten feet away, the estimated distance was within two inches of what I measured using a tape measure. That's accurate enough, in my opinion, to build a crude model of a room for purposes of navigating through it, a common task in AI for stereo vision systems.
I haven't yet seen how good it is at distinguishing distance in objects that are very close to one another using this mechanism. We can easily discriminate depth offsets of a millimeter on objects within two feet. These cameras are not that good, so I doubt they'll be as competent.
So now I have a mechanism that does pretty well at taking a rectangular portion of a scene and finding the best match it can for that portion in the other eye and using it to calculate the distance based on the estimated offset. The next step, then, is to repeat this over the entire image and with ever smaller rectangular regions. I can already see some important challeges, like what to do when the rectangle just contains a solid color or a repeating pattern, but these seem modest complications to an otherwise fairly simple technique. Cool.
[See also Automatic Alignment of Stereo Sameras.]

Comments
Post a Comment