A hypothetical blob-based vision system
As often happens, I was talking with my wife earlier this evening about AI. Given that she's a non-programmer, she's an incredible sport about it and really bright in her understanding of these often arcane ideas.
Because of some questions she was asking, I thought it worthwhile to explain the basics of classifier systems. Without going into detail here, one way of summarizing them is to imagine representing knowledge of different kinds of things in terms of comparable features. She's a "foodie", so I gave the example of classifying cookies. As an engineer, you might come up with a long list of the things that define cookies; especially ones that can be compared among lots of cookies. Like "includes eggs" or a degree of homogeneity from 0 - 100%. Then, you describe each kind of cookie in terms of all these characteristics and measures. Some cookie types will have a "not applicable" or "don't care" value for some of these characteristics. So when confronted with an object that has a particular set of characteristics, it's pretty easy to figure out which candidate object types best fit this new object and thus come up with a best guess. One could even add learning algorithms and such to deal with genuinely novel kinds of objects.
I explained classifier systems to my wife in part to show that they are incomplete. Where does the list of characteristics of the cookie in question come from? It's not that it's not a useful thing, but that it lacks the thing that most all AI system ever made to date lack: a decent perceptual faculty. Such a system could have cameras, chemical analyzers, crush sensors, and all sorts of things to generate raw data, and that might give us enough characteristics to classify cookies. But what happens when the cookie is on a table full of food? How do we even find it? AI researchers have been taking the cookie off the table and putting it on the lab bench for their machines to study for decades, and it's a cheap half-solution.
Ronda naturally asked if it would be possible to have the machine come up with the fields in the "vectors" -- I prefer to think in terms of matrices or database tables -- on its own, instead of having an engineer hand craft those fields? Clever. Of course, I've thought about that and other AI researchers have gone there before. We took the face recognition problem as a new example. I explained how engineers define key points on faces, craft algorithms to find them, and then build a vector of numbers that represent the relationships among those points as found in pictures of faces. The vector can then be used in a classifier system. OK, that's the same as before. So I imagined the engineer instead coming up with an algorithm to look for potential key points in a set of pictures of 100 people's faces. It could then see which ones appear to be repeated in many or most faces and throw away all others. The end result could be a map of key points that are comparable. Those are the fields in the table. OK. So a program can define both the comparable features of faces and then classify all the faces it has pictures of. Pretty cool.
But then, there's that magic step, again. We had 100 people sit in a well-lit studio and had them all face forward, take off their hats and shades, and so on. We spoon fed our program the data and it works great. Yay. But what about the real world? What about when I want to find and classify faces in photographs taken at Disneyland? That's a new problem and starts to bring up the perception question all over again.
At some point, as we were talking over all this, I put the question: let's say your practical goal for a system is to be able to pick out certain known objects in a visual scene and keep track of them as they move around. How can you do this? I was reminded of the brilliant observations Donald D. Hoffman laid out in his Visual Intelligence book, which I reviewed on 5/11/2005. Among other things, Hoffman observed that, given a simple drawing representing an outline of an object, it seems we look for "saddle points" and draw imaginary lines to connect them and end up with lots of simpler "blob" shapes. I went further to suggest that this could be a way to segment a complex shape in such a way that it can be represented by a set of ellipses. The figure below shows a simple example:
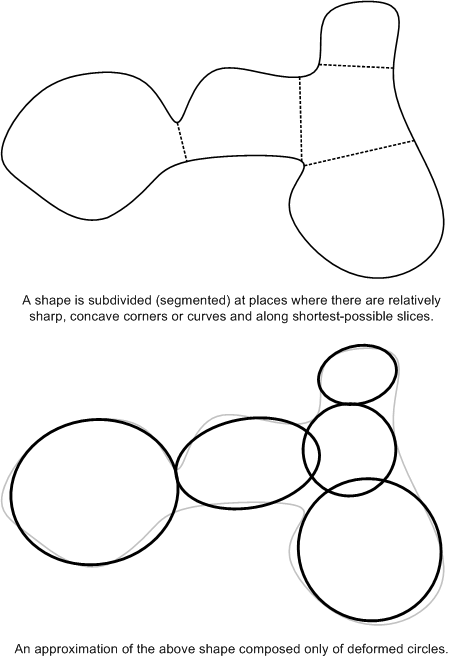
I drew a similar outline in a sandbox at a playground we were walking by and asked her to segment it using these fairly simple rules. Naturally, she got the concept easily. From there, we asked how you could get to the clean line drawings to do the segmenting. After all, vision researchers have been banging their heads against the wall trying to come up with clean segmentation algorithms like this for decades.
I described the most common trick vision researchers have in their arsenal of searching static images for sharp contrasts and approximating lines and curves along them. Not surprisingly, these don't often yield closed loops. That's why I had experimented with growing "bubbles" (see my blog entry and project site) to ensure that there were always closed loops, on the assumption that they would be easier to analyze later than disconnected lines. Following is an illustration:

I found that somewhat unsatisfying because it relies very much on smooth textures, whereas life is full of more complicated textures that we naturally perceive as continuous surfaces. So we batted around a similar idea in which we could imagine "planting" small circles on the image and growing them so long as the image included within the circle is reasonably homogeneous, from a texture perspective. Scientists are still struggling to understand how it is we perceive textures and how to pick them out. I like the idea of simply averaging out pixel colors in a sample patch to compare that to other such patches and, when the colors are sufficiently similar, assume they have the same texture. Not a bad starting point. So imagine segmenting a source image into a bunch of ellipses, where each ellipse contains as large a patch of one single texture as reasonably possible. Why bother?
These ellipses -- we'll call them "blobs" for now -- carry usable information. We switched gears and used hand tools as our example. Let's say we want to learn to recognize hammers and wrenches and such and be able to tell one from another, even when there are variations in designs. Can we get geometric information to jibe with the very one-dimensional nature of databases and algebraic scoring functions? Yes. Our blobs have metrics. Each blob has X / Y coordinates and a surface area; we'll call it its "weight". So maybe in our early experiments, we write algorithms to learn how to describe objects' shapes in terms of blobs, like so:
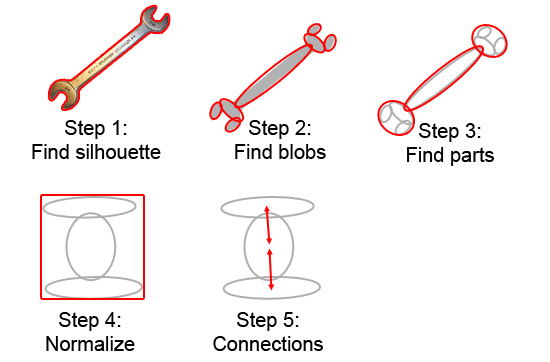
Step 3 is interesting, in that it involves a somewhat computation-heavy analysis of the blobs to see how we can group together bunches of small blobs into "parts" so we can describe our tools in terms of parts; especially if those parts can be found on other tools. In step 4, we use some algorithm to rotate the image (and blobs and parts) so we have them in some well-defined "upright" orientation and stretch it all out so it fits some fixed-sized box, which makes it easier to compare other objects, regardless of their sizes and orientations. In step 5, we look for connections among blobs to help show how they are related. Now, all of these steps are somewhat fictional. They're easy to draw on paper and hard to code. Still, let's imagine we come up with something that basically works for each.
Now, when we see other tools laid out on our bench, we can do the same sorts of analyses and ultimately store the abstract representations we come up with. Perhaps for each object, we store a representation of its parts. One would be picked -- perhaps the center-most -- as the "root" and all the other parts would be available via links to their information in memory. Walking through an object definition would be like following links on web pages. Each part could be described in terms of its smaller parts, and, ultimately, blobs. Information like the number, weights, and relative positions or orientations of blobs and parts to one another can be stored and later compared with those of other candidate objects.
Now here's where things can get interesting. The next step could be to take our now-learned software out into a "real world" environment. Maybe we give it a photograph of the wrench in a busy scene. We segment the entire scene into blobs, as before. But this time, we do an exhaustive search of all combinations of blobs against all known objects' descriptions.
At this point, the veteran programmer has the shakes over the computation time required for all this. Get over it and pretend other engineers work on optimizing it all later. And besides, we have an infinitely fast computer in our thought experiment; something every AI researcher could use.
It starts seeming like we can actually do this; like we can have a system that is capable of actually perceiving hand tools in a busy scene. Maybe our next step is to feed video to the program, where a camera pans across the busy scene. This time, instead of our program looking at each individual frame as a whole new scene, we start with the assumption of object persistence. In frame 1, we found the wrench. In frame 2, we search for the wrench immediately at the same place. Once we found the wrench in frame 1, we worked back down to the source image and picked out the part of the bitmap that is strongly associated with the wrench and try doing a literal bitmap match in frame 2 around the area it was in frame 1. Sure enough, we find it, perhaps just a little to the right. We assume it's the same wrench. So now, we've saved a lot of computation by doing more of a "patch match" algorithm.
Now we not only have our object isolated, but we also now have information about its movement in time and can make a prediction about where it might be in frame 3. Maybe in frame 1, we found 2 wrenches and 1 hammer. Maybe as we track each one's movement from frame to frame, we look to see if it's all consistent in such a way that suggests maybe the camera is moving or that they are all on the same table or otherwise meaningfully related to one another in their dynamics. New objects might be discovered, as well, using "learning while performing" algorithms like I described in a recent blog entry. So much potential is opened up.
I don't mean to suggest this is exactly how a visual perception algorithm should work. I just loved the thought experiment and how it showed how engineers could genuinely craft a system that can truly perceive things. And it illustrates a lot of features I consider highly valuable, like learning, pattern invariance, geometric knowledge, hierarchic segmentation of objects into "parts", bottom-up and top-down processes to refine percepts, object permanence, and so on.
Now, about the code. I'll have to get back to you on that.
Because of some questions she was asking, I thought it worthwhile to explain the basics of classifier systems. Without going into detail here, one way of summarizing them is to imagine representing knowledge of different kinds of things in terms of comparable features. She's a "foodie", so I gave the example of classifying cookies. As an engineer, you might come up with a long list of the things that define cookies; especially ones that can be compared among lots of cookies. Like "includes eggs" or a degree of homogeneity from 0 - 100%. Then, you describe each kind of cookie in terms of all these characteristics and measures. Some cookie types will have a "not applicable" or "don't care" value for some of these characteristics. So when confronted with an object that has a particular set of characteristics, it's pretty easy to figure out which candidate object types best fit this new object and thus come up with a best guess. One could even add learning algorithms and such to deal with genuinely novel kinds of objects.
I explained classifier systems to my wife in part to show that they are incomplete. Where does the list of characteristics of the cookie in question come from? It's not that it's not a useful thing, but that it lacks the thing that most all AI system ever made to date lack: a decent perceptual faculty. Such a system could have cameras, chemical analyzers, crush sensors, and all sorts of things to generate raw data, and that might give us enough characteristics to classify cookies. But what happens when the cookie is on a table full of food? How do we even find it? AI researchers have been taking the cookie off the table and putting it on the lab bench for their machines to study for decades, and it's a cheap half-solution.
Ronda naturally asked if it would be possible to have the machine come up with the fields in the "vectors" -- I prefer to think in terms of matrices or database tables -- on its own, instead of having an engineer hand craft those fields? Clever. Of course, I've thought about that and other AI researchers have gone there before. We took the face recognition problem as a new example. I explained how engineers define key points on faces, craft algorithms to find them, and then build a vector of numbers that represent the relationships among those points as found in pictures of faces. The vector can then be used in a classifier system. OK, that's the same as before. So I imagined the engineer instead coming up with an algorithm to look for potential key points in a set of pictures of 100 people's faces. It could then see which ones appear to be repeated in many or most faces and throw away all others. The end result could be a map of key points that are comparable. Those are the fields in the table. OK. So a program can define both the comparable features of faces and then classify all the faces it has pictures of. Pretty cool.
But then, there's that magic step, again. We had 100 people sit in a well-lit studio and had them all face forward, take off their hats and shades, and so on. We spoon fed our program the data and it works great. Yay. But what about the real world? What about when I want to find and classify faces in photographs taken at Disneyland? That's a new problem and starts to bring up the perception question all over again.
At some point, as we were talking over all this, I put the question: let's say your practical goal for a system is to be able to pick out certain known objects in a visual scene and keep track of them as they move around. How can you do this? I was reminded of the brilliant observations Donald D. Hoffman laid out in his Visual Intelligence book, which I reviewed on 5/11/2005. Among other things, Hoffman observed that, given a simple drawing representing an outline of an object, it seems we look for "saddle points" and draw imaginary lines to connect them and end up with lots of simpler "blob" shapes. I went further to suggest that this could be a way to segment a complex shape in such a way that it can be represented by a set of ellipses. The figure below shows a simple example:
I drew a similar outline in a sandbox at a playground we were walking by and asked her to segment it using these fairly simple rules. Naturally, she got the concept easily. From there, we asked how you could get to the clean line drawings to do the segmenting. After all, vision researchers have been banging their heads against the wall trying to come up with clean segmentation algorithms like this for decades.
I described the most common trick vision researchers have in their arsenal of searching static images for sharp contrasts and approximating lines and curves along them. Not surprisingly, these don't often yield closed loops. That's why I had experimented with growing "bubbles" (see my blog entry and project site) to ensure that there were always closed loops, on the assumption that they would be easier to analyze later than disconnected lines. Following is an illustration:
I found that somewhat unsatisfying because it relies very much on smooth textures, whereas life is full of more complicated textures that we naturally perceive as continuous surfaces. So we batted around a similar idea in which we could imagine "planting" small circles on the image and growing them so long as the image included within the circle is reasonably homogeneous, from a texture perspective. Scientists are still struggling to understand how it is we perceive textures and how to pick them out. I like the idea of simply averaging out pixel colors in a sample patch to compare that to other such patches and, when the colors are sufficiently similar, assume they have the same texture. Not a bad starting point. So imagine segmenting a source image into a bunch of ellipses, where each ellipse contains as large a patch of one single texture as reasonably possible. Why bother?
These ellipses -- we'll call them "blobs" for now -- carry usable information. We switched gears and used hand tools as our example. Let's say we want to learn to recognize hammers and wrenches and such and be able to tell one from another, even when there are variations in designs. Can we get geometric information to jibe with the very one-dimensional nature of databases and algebraic scoring functions? Yes. Our blobs have metrics. Each blob has X / Y coordinates and a surface area; we'll call it its "weight". So maybe in our early experiments, we write algorithms to learn how to describe objects' shapes in terms of blobs, like so:
Step 3 is interesting, in that it involves a somewhat computation-heavy analysis of the blobs to see how we can group together bunches of small blobs into "parts" so we can describe our tools in terms of parts; especially if those parts can be found on other tools. In step 4, we use some algorithm to rotate the image (and blobs and parts) so we have them in some well-defined "upright" orientation and stretch it all out so it fits some fixed-sized box, which makes it easier to compare other objects, regardless of their sizes and orientations. In step 5, we look for connections among blobs to help show how they are related. Now, all of these steps are somewhat fictional. They're easy to draw on paper and hard to code. Still, let's imagine we come up with something that basically works for each.
Now, when we see other tools laid out on our bench, we can do the same sorts of analyses and ultimately store the abstract representations we come up with. Perhaps for each object, we store a representation of its parts. One would be picked -- perhaps the center-most -- as the "root" and all the other parts would be available via links to their information in memory. Walking through an object definition would be like following links on web pages. Each part could be described in terms of its smaller parts, and, ultimately, blobs. Information like the number, weights, and relative positions or orientations of blobs and parts to one another can be stored and later compared with those of other candidate objects.
Now here's where things can get interesting. The next step could be to take our now-learned software out into a "real world" environment. Maybe we give it a photograph of the wrench in a busy scene. We segment the entire scene into blobs, as before. But this time, we do an exhaustive search of all combinations of blobs against all known objects' descriptions.
At this point, the veteran programmer has the shakes over the computation time required for all this. Get over it and pretend other engineers work on optimizing it all later. And besides, we have an infinitely fast computer in our thought experiment; something every AI researcher could use.
It starts seeming like we can actually do this; like we can have a system that is capable of actually perceiving hand tools in a busy scene. Maybe our next step is to feed video to the program, where a camera pans across the busy scene. This time, instead of our program looking at each individual frame as a whole new scene, we start with the assumption of object persistence. In frame 1, we found the wrench. In frame 2, we search for the wrench immediately at the same place. Once we found the wrench in frame 1, we worked back down to the source image and picked out the part of the bitmap that is strongly associated with the wrench and try doing a literal bitmap match in frame 2 around the area it was in frame 1. Sure enough, we find it, perhaps just a little to the right. We assume it's the same wrench. So now, we've saved a lot of computation by doing more of a "patch match" algorithm.
Now we not only have our object isolated, but we also now have information about its movement in time and can make a prediction about where it might be in frame 3. Maybe in frame 1, we found 2 wrenches and 1 hammer. Maybe as we track each one's movement from frame to frame, we look to see if it's all consistent in such a way that suggests maybe the camera is moving or that they are all on the same table or otherwise meaningfully related to one another in their dynamics. New objects might be discovered, as well, using "learning while performing" algorithms like I described in a recent blog entry. So much potential is opened up.
I don't mean to suggest this is exactly how a visual perception algorithm should work. I just loved the thought experiment and how it showed how engineers could genuinely craft a system that can truly perceive things. And it illustrates a lot of features I consider highly valuable, like learning, pattern invariance, geometric knowledge, hierarchic segmentation of objects into "parts", bottom-up and top-down processes to refine percepts, object permanence, and so on.
Now, about the code. I'll have to get back to you on that.

Comments
Post a Comment